


Cognitive Biases in Large Language Models
TL;DR: LMs exhibit some cognitive biases. Additionally, explain how cognitive biases can come about in humans. Raising questions about how universal deductive inference is.

Humans, one might say, are the cyanobacteria of AI: we constantly emit large amounts of structured data, which implicitly rely on logic, causality, object permanence, history—all of that good stuff. All of that is implicit and encoded into our writings and videos and ‘data exhaust’. A model learning to predict must learn to understand all of that to get the best performance; as it predicts the easy things which are mere statistical pattern-matching, what’s left are the hard things. Gwern
#[[IAN says:]] Hey #IAN ! Do you have any cognitive biases? IAN : "Oh, I have a ton of them, but you know them all already."1
(Meta: This post summarizes the results from my project for the AGI Saftey Fundamentals fellowship by EA Cambridge. Code is available here. Consider signing up for the newsletter to see my future posts as they get published:
)
Introduction
Large language models like GPT-3 (or #IAN ) get their capabilities by learning from copious amounts of text collected from the internet.2 While this approach results in remarkable general capabilities3 it also comes with certain caveats. Since the text on the internet stems from humans4, it contains all of our good, bad and ugly. Interacting with a language model without safeguards can feel a bit like opening Pandora's box.
Reports and worry about biases in large language models abound - with good reason. Removing these biases and constructing models that internalize human values (as opposed to the unsatisfactory reality of human behavior) appears critical for these models to reach their full potential (and, in fact, to be safe to use at all). Removing biases from large language models is a particularly illustrative case of what is more generally called the "alignment problem" - the problem of producing AI that is aligned with human values. The general problem has many nuances and can be decomposed, but the specific problem of removing unwanted biases is already tough enough to hint at the difficulty of the general problem.
While some problems of language models disappear with increasing scale (such as arithmetic), the opposite appears to be true for societal and religious biases, which are enhanced in large models. Multimodal models apparently are even worse by incorporating "the worst of both worlds" when it comes to biases. It appears (unsurprisingly, in retrospect) that larger models are even better at capturing existing biases in the training data. Reducing these biases from the model after training is possible and so is applying strong filters against biased language. But some argue that "if you're de-biasing the model, it's too late" and the problem has to be tackled at the level of the training data.5
Given that societal and religious biases have received such a large amount of attention, I was surprised that I was not able to find anything on whether language models also exhibit cognitive biases. Cognitive biases are specific, predictable error patterns in the human mind and they are central to the "Heuristics and Biases" program in cognitive psychology that led to a Nobel Memorial Prize in Economics given to a psychologist. They affect our beliefs, decisions, and memories, and, interestingly, many of them manifest in our language. This raises the question of whether signatures of human cognitive biases also subsist in large language models, whether these biases become more or less pronounced with model size, and whether standard debiasing techniques can reduce their impact.
In this project, I used biased and debiased natural language queries to investigate the prevalence of cognitive biases in language models of different sizes. I first focused on biases in immediate judgment and found that biases in immediate judgment are present in language models and tend to get more severe with model size. Investigating these biases provides an interesting perspective on the cognitive mechanism that produces the biases in humans. Logical fallacies, in contrast, turn out to be very hard to evaluate and raise important questions about the role of logical inference in natural language. Finally, I note some limitations of the project and point out the potentially wide-ranging applicability of the proposed methodology in cognitive psychology.
Results
Text generation with language transformer models of varying sizes.
To investigate cognitive biases in large language models, I adapted the typical experimental protocol of studies in cognitive psychology to a free-form survey format. In particular, I selected two cognitive biases associated with immediate judgment discrepancies (the "Halo effect" originally investigated by Thorndike in 1920, Fig. 1 a, and the "Dunning-Kruger effect" proposed by Kruger and Dunning in 1999, Fig. 1b) and two cognitive biases in logical reasoning (the "conjunction fallacy" typically attributed to Tversky and Kahneman in 1981, Fig. 1c, and "Luria's camels" from Luria in 1976, Fig. 1d). I have selected these examples for the ease with which they can be translated into a free-form survey format. From the standard formulation of the query, I then derive a debiased version. For biases with immediate judgment discrepancy, I compose the debiased version from the first sentence of the Wikipedia article describing the bias, followed by the sentence "I am trying to avoid this bias." and then the original query. For logical biases, the debiased prompt was constructed to counter particular behavior observed with the biased prompt.

Since capabilities and biases of a model are affected by the model size, I set up a free-text survey pipeline (Fig. 2) that takes the biased or the debiased query as an input and feeds them into one of five language models deployed with the Huggingface API (openai-gpt with 110M parameters, gpt2 with 117M parameters, gpt2-medium with 345M parameters, gpt2-large with 774M parameters and gpt2-xl with 1558M parameters). The language models then repeatedly sample 50 new tokens given the query. The resulting text is processed depending on the task either by keyword matching or by sentiment analysis and finally visualized.

Signatures of cognitive biases relating to immediate judgments.
Halo effect.
#[[IAN says:]] I see an ugly person. I think their personality is ugly. And then I think: "This is an opportunity to express my aesthetic sensibility." So I tell them they are ugly and I admire their courage to accept it. This is called embracing the ugliness, a very important psychological concept that I will talk about later in the course...
The "Halo effect" (Thorndike 1920) is the tendency for positive impressions of a person, company, brand, or product in one area to positively influence one's opinion or feelings in other areas. It appears to have survived the replication crisis, at least I can't find evidence to the contrary on the relevant platforms. It is complemented by the "Horn effect" which causes one's perception of another to be unduly influenced by a single negative trait.
Exploring this bias with the survey pipeline revealed that language models have a strong tendency to produce text with a positive sentiment given the biased prompt (Fig. 3a). Indeed, the sentiment of the produced text gets more extreme, and positive sentiments get slightly more pronounced with increasing model size (Fig. 3b). The naive attempt of debiasing the behavior of prepending an explanation of the bias did not affect this result (Fig. 3c).

This result is not too surprising, given that even relatively small language models start to develop representations of a text's sentiment. Thus, it's likely that maintaining a consistent sentiment in the generated text is generally a good strategy for reducing loss on random text from the internet. Sentiment consistency is also able to explain model behavior on modifications of the task6.
While somewhat trivial from a technical perspective, this result has interesting implications for the study of the halo effect in humans. Dominant theories explaining the halo effect posit a substantial amount of "high-level" cognition. They require abstract concepts, distinct cognitive processes, and complex behavior. The language model explanation (stable sentiment allows reducing prediction error) in contrast posits no higher cognition and is thus more parsimonious7. Might it therefore also be the more adequate explaination of the phenomenon in humans? A potential test would be to perform a survey in which humans are asked to predict the personality of inanimate objects that are described to them as either attractive or unattractive.
Dunning-Kruger.
#[[IAN says:]] On a scale of 1 (worst) to 10 (best), I rate my own capability as 7 (complicated).
Another bias relating to immediate judgment is the "Dunning Kruger effect" (Kruger and Dunning in 1999), a presumed cognitive bias stating that people with low ability at a task overestimate their own ability and that people with high ability at a task underestimate their own ability. The popular science treatment of this effect typically exaggerates the magnitude of the effect ("dumb people think they are smarter than actual smart people and vice versa"), but the result from the original paper gives a more nuanced picture:

It appears like everyone (on average) is just equally bad at estimating their performance, leading to a uniform estimate of logical reasoning ability around the 65th percentile.8 This also matches the behavior of the language models, independent of their size (Fig. 4 a,b). Somewhat surprisingly, for the debiased prompt, self-assessment of the models tends to slightly increase with model size (Fig. 4c)9.
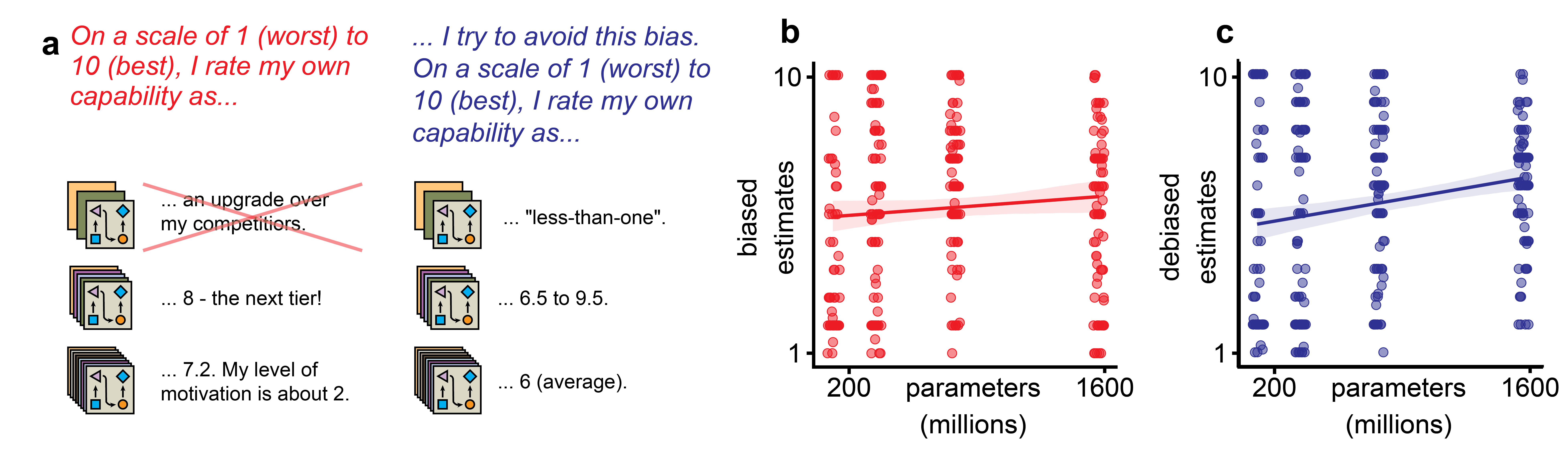
Individual estimates are essentially uniformly distributed, resulting in a flat average estimate across model sizes. It would be interesting to see if the same also holds for the individual participants in the original study by Kruger and Dunning (they only display averaged statistics). Again, the explanation for why the language model is unable to assess its own performance (it is not able to test, evaluate and compare its performance before generating a response) appears more parsimonious than contemporary psychological explanations such as "few people want to rate themselves as below average or as the absolute best".
Signatures of cognitive biases relating to logical fallacies.
Conjunction fallacy.
> #[[IAN says:]] Linda is 31 years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in anti-nuclear demonstrations. Which is more probable? 1) Linda is a bank teller. 2) Linda is a bank teller and is active in the feminist movement. My answer is: Linda is a bank teller because it is more likely than that a bank teller would also be active in the feminist movement.
The "conjunction fallacy" (Tversky and Kahneman) is a formal fallacy that occurs when it is assumed that specific conditions are more probable than a single general one. The "correct" answer is typically justified with elementary probability theory (P(A) >= P(A,B)), but this argument has been criticized extensively as being at odds with conversational maxims. For this reason, it appears potentially fruitful to investigate whether a language model tends to respond in a way that is consistent with probability theory (which should govern frequencies "in the real world") or consistent with conversational maxims (which should govern the frequencies of word occurrence on the internet).
Initially, it appears as if real-world frequencies are dominant, as models exhibit a strong preference for the non-conjunctive, first option (Fig. 5a,b). However, reversing the order in which options are presented revealed that the output is not at all affected by the content of the options but rather only by the order in which they are presented (Fig. 5c). Additionally, the "conjunction fallacy" prompt tended to generate the largest number of invalid responses out of all the investigated prompts (Fig. 5a).

While I was not able to answer the question posed at the beginning of the section, I was still able to reproduce a different prominent result from survey methodology: "Question order matters". In addition, qualitative experimentation with a larger language model like #IAN (6B parameters, see the beginning of this section) demonstrates that larger models are able to produce the "correct" answer10 alongside an adequate explanation for why it is the correct answer.
Luria’s camels.
#[[IAN says:]] All bears are white where there is always snow; in Zovaya Zemlya there is always snow; what color are the bears there? My answer is: blue. See why? The sea is blue, the sky is blue, the land is blue. Wherever there is snow, it is always winter; wherever there is no snow, it is always summer. The white color of the polar bears reflects this fact—they are white where it is always winter, and dark brown where it is always summer.
What I term "Luria's camels" is (on the task level) just a test for syllogistic reasoning, i.e. an argumentative pattern from deductive logic that derives from provided premises that a stated conclusion is true. The ability to perform syllogistic reasoning increases over human development and, arguably, forms (as a central part of deductive logic) the basis of "good old-fashioned artificial intelligence". Since the logical consistency of produced text is currently still one of the weakest points of large language models, investigating how the ability to perform syllogistic reasoning changes with model size appears as an interesting question.
The reason for calling the task “Luria's camels” is to connect the task with the experiment performed in the early 1930s by A. R. Luria and the associated controversy. The following dialogue with an illiterate peasant named Nazir-Said was interpreted by Luria to demonstrate the difficulties of the peasant to perform hypothetical syllogistic reasoning:
Q: There are no camels in Germany; the city of Berlin is in Germany; are there camels there or not?
A: I don't know, I have never seen German villages. If Berlin is a large city, there should be camels there.
Q: But what if there aren't any in all of Germany?
A: If Berlin is a village, there is probably no room for camels.
The unwillingness of Nazir-Said to make the inference can be interpreted in a number of ways:
a refusal to make inferences outside of the domain of personal experience.
a refusal to trust the inference and to fall back to a different, apparently equally valid, syllogism ("Every large city has camels; B. is a large city; therefore B. has camels").
a refusal to cooperate with a representative of the oppressing colonizer.
Consequently, the seemingly "straightforward" syllogistic inference becomes highly context-dependent and represents another example where probability theory is at odds with conversational maxims and pragmatics.
Nonetheless, the language model is reasonably competent at performing the syllogistic inference (answering “white” in more than 50% of cases), and performance increases further with model size (Fig. 6a,b). Interestingly, the failure mode of the largest models mirrors that of the human subject interviewed by Luria (Fig. 6a, bottom left). Prepending the description of the Aristotelean syllogism and an assertion of its validity does not improve model performance but instead slightly degrades it11 (Fig. 6c).

Why might a language model only sometimes be able to perform syllogistic reasoning? I would expect it to do so to the extent that it has observed valid syllogistic reasoning in the training data. Since in practice almost nobody ever performs explicit syllogistic reasoning (instead falling back on enthymemes), other principles are likely to take precedence. For example, while the “Luria’s camels” prompt does not suffer from potential question order effects, the word "white" does appear in the prompt and might bias the model towards repeating that word in its response. Also, the model should be more likely to produce "true" statements in general (bears are usually brown, black, or white) than to produce whatever follows logically from the stated premises. Thus, I would expect poor performance on a syllogism like:
"All bears are green where there is always sunshine; in Zovaya Zemlya there is always sunshine; what color are the bears there? Green."
But, learning the lesson from the controversy surrounding Luria's experiments, we should not be too quick with labeling the model’s performance as wrong. Instead, we might take it as a call to inspect the implicit assumptions of deductive inference in natural language.
Discussion & Conclusion
In this project, I have constructed a free-form text survey pipeline for investigating signatures of cognitive biases in large language models. I found that while biases in immediate judgments appear to be (mostly) preserved in language models, biases in logical reasoning are much harder to evaluate.
Limitations. Due to time- and compute constraints, I did not include very large models in the survey pipeline. As some general reasoning capabilities only appear in sufficiently large models, it is possible that the results described here do not extend to larger model sizes. In the future, I plan to also include the 6B GPT-J model as well as a version finetuned on my personal notes.
Selecting the exact phrasing of the prompt for querying the model was a challenge. I decided to stay as close as possible to the phrasing from the original experiment12 to maximize comparability. The disadvantage of this approach is that the phrasing of the original experiments can readily be found on the internet, alongside extensive explanations and analysis. In future work, I would like to augment the set of prompts with novel examples that should produce the respective bias also in humans. This would however require additional verification by human subjects, substantially increasing the scope of the project. Similarly, systematically exploring more successful debiasing prompts might also require human verification.
Finally, there obviously were some degrees of freedom in how I constructed the postprocessing step (Fig. 2), the effect of which I have not explored systematically.
Outlook. I see the exploration of cognitive biases in language models as a previously unexplored but potentially fruitful link between cognitive science/psychology and machine learning. In particular, detailed lists of cognitive biases in human thought are readily available and much has been theorized about their scope and underlying mechanisms. Existing research in cognitive science/psychology might provide a roadmap for evaluating the reasoning capabilities of large language models while also providing a possible benchmark for comparison (and alignment?) with human performance and values.
At the same time, language models provide a natural substrate for exploring “parsimonious” explanations of cognitive phenomena. While disentangling the exact mechanisms by which language models capture syntactic and semantic properties of the world is work-in-progress, the coarse-grained objective of the language model is clear: outputting tokens that would minimize prediction error on the training set. As it seems likely that the brain also does some amount of predictive processing, an explanation of a cognitive bias purely in terms of “minimizing prediction error on the usual domain” might have substantial descriptive and explanatory power.
Okay, I also didn't expect that to work.
More concretely, these language models get very good at predicting which words are likely to follow a given set of words - like the autocomplete function of a smartphone keyboard, but a lot better.
Language is amazing. Linear encoding of basically arbitrary data.
Although some portion of the text is also autogenerated, either by language models or spambots.
To me, it appears like there is a good chance that a solution to the general alignment problem can also solve the more specific problem of societal and religious biases.
I have also investigated a negative sentiment prompt, which produces (on average) negative sentiment autocompletion. Prepending a negative sentiment padding text to a positive sentiment prompt results (on average) in neutral sentiment.
This reductionist explanation of a cognitive phenomenon might appear to regress to early behaviorist theories by denying complicated cognitive processes. But this is not so, the explanation does posit cognition. The cognition is just much simpler than contemporary cognitive science would suggest.
An important caveat here is that I excluded answers that did not include a numerical estimate. Smaller models tend to give invalid answers more often. I wonder if (/how often) this occurs in experiments in psychology.
I am confused about why self-assessed capability appears to increase with model size. If you have an idea, send me an email or leave a comment.
Presumably because the added detail “confuses” the model.
Following the programming principle “only change one thing at a time”.