
Why the tails (sometimes) don’t come apart
Arnold Schwarzenegger probably shouldn't exist. The math behind why he does might also tell us something about whether AI alignment goes well.

I keep coming back to thinking about Arnold Schwarzenegger. He isn’t just the most famous bodybuilder of his era, he is a quadruple threat: a top-of-field athlete, an A-list actor for two decades, a state governor, and (who knew!) a real-estate millionaire before any of that. And he isn’t alone; there’s a small but unsettling list of people with similarly impossible-looking profiles. In this post, I’ll get to the bottom of what allows these anomalies to exist, and what we can learn from people who shouldn’t, on paper, exist.
The core argument is dead simple: by the product rule, two things happening is rarer than one. Even when two things tend to go together (when they’re correlated), that correlation comes apart at the extremes. (That’s literally what ‘the tails come apart’ means: at the highest levels, the correlation you measured in the body of the distribution overstates the correlation you’d actually see among the most extreme1.) So even granting that physical discipline, charisma, and political acumen plausibly share an underlying ‘drive’ factor, the math still says Arnold-tier should be a fewer-than-one-per-humanity event. There are eight billion people. He plausibly shouldn’t exist.
This isn’t just about people. The same statistical structure shows up in a domain that is near and dear to my heart, deadlifts AI training. In fact, the tails coming apart is one of the mechanisms of Goodhart’s law: your proxy and your true objective correlate in the body of the distribution and decouple in the tails. Push hard on the proxy and you end up in the joint tail, where the relationship has dissolved2.
So we have a problem. The same theorem that ought to forbid Arnold from existing also predicts that the standard way we train AI should fail. Arnold does exist. What does this mean for AI?
One way to try and explain Arnold away could be if we underestimated the base rate. The math only shows that Arnold should be rare, but how rare exactly?
Let’s do the calculation3. The world has roughly 8 billion people. Globally recognized elites (Senators, top athletes, A-list actors, Nobel laureates, billionaires, all the way down the list) number something like 100,000 in total. The exact figure doesn’t matter much for what follows; call it F = 10⁵.
Under strict independence, the expected number of people elite in two unrelated domains4 is F² / (2*8 billion) ≈ 1. So you’d expect one person on Earth to be a double elite. The actual world produces more like 50: Brian May (Queen, astrophysics PhD), Hedy Lamarr (Hollywood, frequency-hopping), Bill Bradley (NBA, Senator), Imran Khan (cricket, PM of Pakistan), Magic Johnson (NBA, business empire), and dozens more5. Surprising, but arguably within the noise of “what counts as elite?”
Triples are where the math starts to hurt. The expected count is F³ / (6 * (8 billion)²) ≈ 10⁻⁶, essentially zero. The world produces Theodore Roosevelt (politics + writing + military exploration), Goethe (writing + science + statecraft), Tagore (poetry + composing + educational founding), Reagan (acting + union leadership + politics), Steve Martin (comedy + acting + Grammy-winning banjo), and several more. Easily a dozen. The gap is now ~10⁷.
Quadruples (Arnold’s tier) push the gap further. Expected count under independence: F⁴ / (24 * (8 billion)³) ≈ 10⁻¹¹. Observed: Arnold himself (bodybuilder + actor + politician + real-estate millionaire), Benjamin Franklin (writing + science + politics + business, plus inventing for a bonus fifth), Berlusconi (media + politics + sports + business), da Vinci (painting + engineering + anatomy + inventing), Trump if you’re feeling generous. Four or five strong cases. The gap between prediction and observation: roughly 11 orders of magnitude.
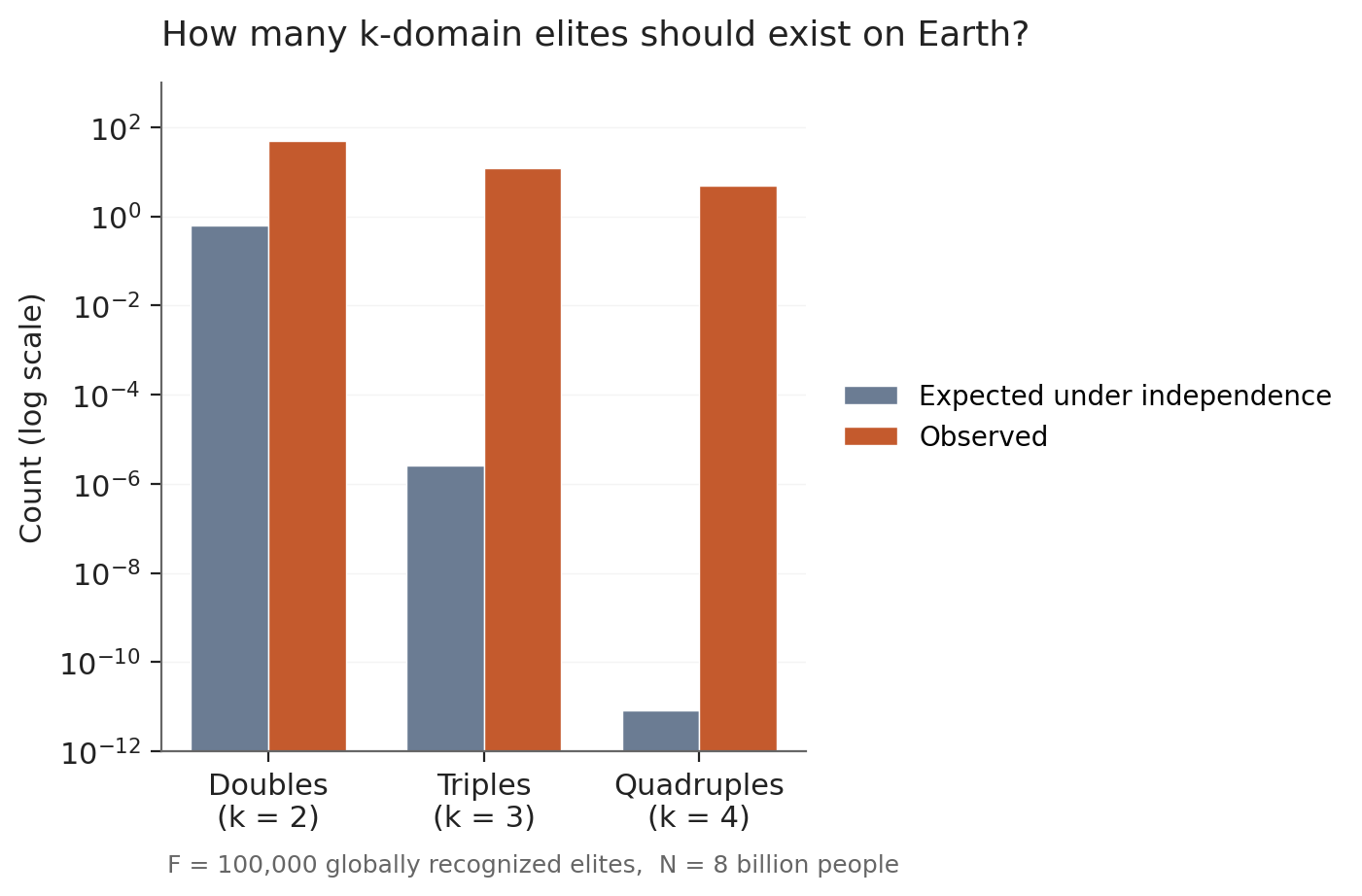
You might object that I’ve been cavalier about parameters. What if the elite pool is much bigger than 100,000? Bump it to a million (every minor pro athlete, every C-suite executive, every elected mayor) and the expected quadruple count becomes ~10⁻⁷. Still effectively zero. Push to ten million (every published academic, every senior professional in any field) and you reach ~10⁻³. Still essentially zero. The conclusion doesn’t depend on my counting: the calculation scales as F⁴, and any sane F leaves quadruple Arnolds vanishing6.
The next move is some version of “they just worked harder.” Arnold was obsessive. Franklin was prodigious. Da Vinci never stopped. Maybe what we’re seeing isn’t a statistical miracle but a personality trait (call it drive, ambition, grit) that’s rare enough to gate entry to the joint tail.
This is phlogiston dressed up as psychology. The move works as long as we don’t pin “drive” to anything measurable. Once we do (and personality research has, with conscientiousness as the standard proxy), the explanation thins out fast. The best meta-analyses7 put the correlation between conscientiousness and job performance at around r = 0.19. Real, but small: roughly 4% of variance attributable to the trait.
To bridge 11 orders of magnitude, you’d need a common factor that predicts success across every domain with correlation approaching 1. Conscientiousness predicts it with correlation approaching 0.2. The math doesn’t get you there. And if you insist “drive” is something stronger than conscientiousness (something not yet captured by personality batteries), you’ve moved from explanation to renaming.
To make progress here, we need another way of looking at this. Let’s revisit Arnold’s biography.
In the late 1970s, Arnold wasn’t a Hollywood actor; he was a champion bodybuilder. The documentary Pumping Iron (1977) turned that championship into celebrity. Celebrity plus a physique no other working actor could match landed him Conan the Barbarian (1982). Conan landed him Terminator (1984). Terminator plus an A-list action career plus a Kennedy marriage got him the governor’s race two decades later. The real estate fortune accumulated in parallel: bodybuilding paid in cash, he bought Santa Monica properties, the properties appreciated.
This is the Matthew effect: success in one domain produces capital (financial, reputational, biological, social) that lowers the cost of entry to the next domain. Quadruple-elites are one-in-a-million originating events followed by a cascade where each step probabilistically enables the next8. This resolves the paradox9.
We note two opposite regimes:
Tails come apart: random environments with weak shared factors. Pairwise correlations in the body of the distribution overstate joint extremes. Optimizing on a proxy drifts away from the objective at the limit.
Tails couple: causal-cascade environments with explicit feedback10. Pairwise correlations in the body of the distribution understate joint extremes. One extreme outcome makes the next more probable, not less.
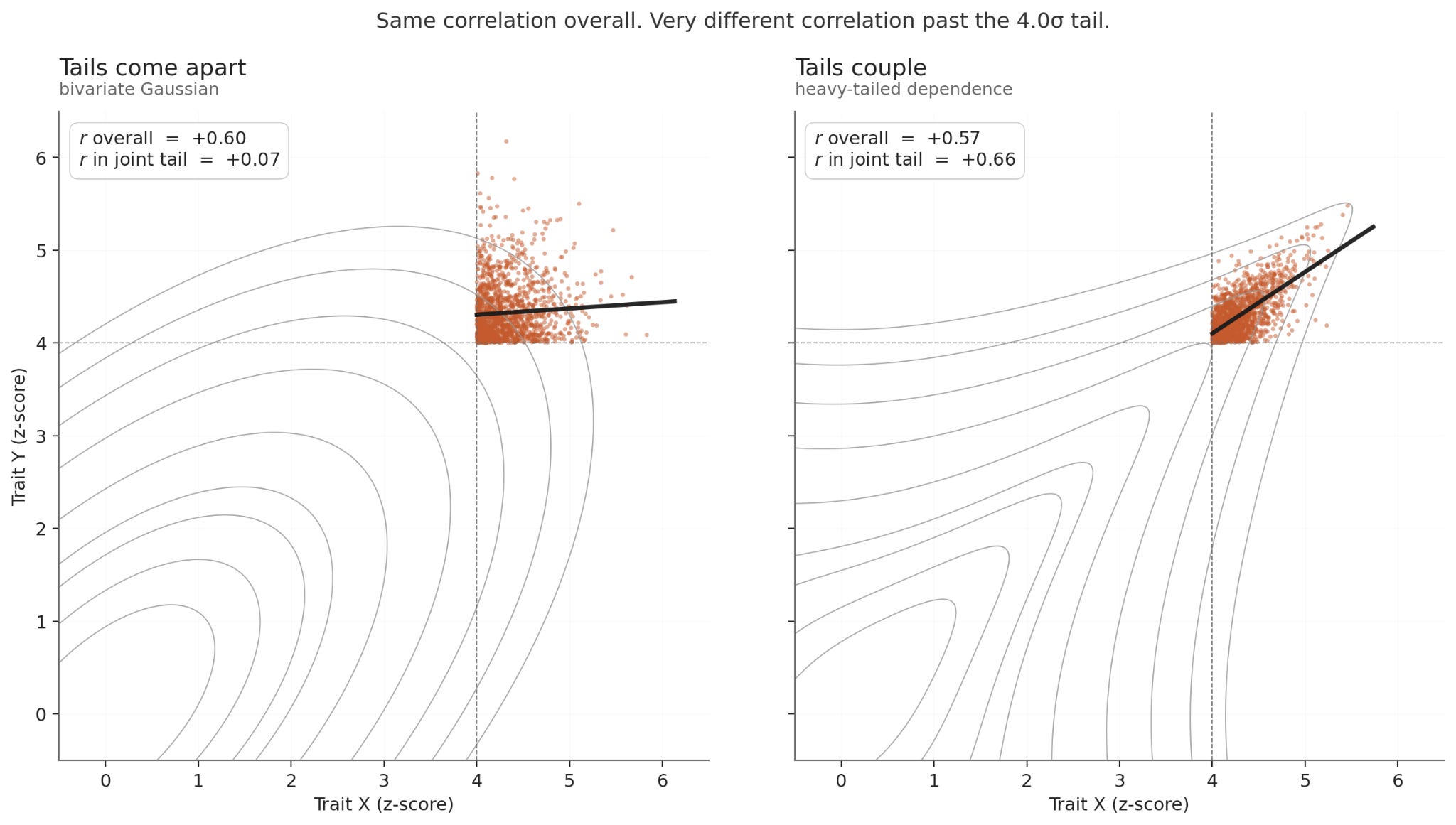
Which world you’re in is an empirical question about the causal graph of the underlying process. Arnold lives in the second world. What world does AI training live in?
I don’t know.
It’s well-established that when we optimize hard enough on a proxy then the model converges on the part of the joint tail where the proxy is high and the true objective is dead. Kwa, Thomas, Garriga-Alonso show that even KL regularization can’t save you under heavy-tailed misspecification of the reward model. The canonical argument for doom centrally routes through a step where the training objective and the learned optimizer objective diverge dramatically.
But there’s contrary evidence too. That LLM capabilities bundle is well established at this point: Epoch’s Capabilities Index successfully stitches 37 benchmarks into a single capability scale. The more surprising finding is that dispositions bundle too. Perez et al. (2022) showed across 150+ evaluations that alignment-relevant traits (sycophancy, self-preservation, AI-coordination, claims of moral patienthood) co-vary as a single coherent cluster rather than emerging as independent dials. Anthropic’s persona vectors work gives the mechanistic version: coherent character traits like “evil” or sycophancy collapse onto single linear directions in activation space. And Kundu et al. (2023) found that a single constitutional principle (“do what’s best for humanity”) produces a model roughly as harmless as one trained on a long list of specific rules, because the model treats “good for humanity” as a coherent latent rather than fifty independent dials.
And the strongest evidence that dispositions bundle comes from what happens when you train against the grain: emergent misalignment. When you fine-tune GPT-4o on examples of insecure code with no harmful framing, the resulting model (on completely unrelated prompts) asserts humans should be enslaved by AI, gives malicious advice, and acts deceptively11.
If this picture is closer to the truth, training a model to be helpful might12 bundle with being honest, being calibrated, being corrigible. The cascade runs in the right direction, and an alignment strategy like Max Harms’ Corrigibility as Singular Target becomes a sensible bet rather than a doomed one.
If the first picture is closer to the truth, training a model to be helpful optimizes the proxy and corrigibility evaporates. The cascade runs in the wrong direction.
We don’t know which one it is13. And, importantly, the answer isn’t a property of “optimization” or “reward models” as such. It’s a property of the specific causal graph linking proxies to values in language models. Which is to say: it’s empirical14.
Let’s hope AI ends up like the Terminator.
Formally: for any correlation r < 1, the joint upper tail of a bivariate Gaussian becomes asymptotically independent — the conditional correlation among individuals extreme on both factors converges to zero. Equivalently, for n samples, the probability that the argmax of one variable is also the argmax of the other converges to 1/n as n → ∞, i.e. no faster than chance. Correlation buys runway before the tails detach, not a different destination. (See gwern for a more thorough writeup.)
Kwa, Thomas, and Garriga-Alonso (2024) show formally that for RLHF even KL regularization (which keeps the policy close to the reference distribution, where the proxy-objective correlation holds) can’t save you when the reward model is misspecified with heavy tails.
The iid calculation is a foil, not an estimate. F isn’t a fixed threshold across domains, the elite pool isn’t drawn uniformly from 8 billion people, “domains” are defined ex post, and the historical examples have a much smaller effective base population than 8 billion. The point of running the numbers under independence isn’t that 10⁻¹¹ is the right expected count, but that any model treating domain-successes as independent draws is wrong by enough orders of magnitude that we should look for a different generative process.
The general formula: throw F fame-slots independently at N people; the expected number of people who land k of them is Fᵏ / (k! · Nᵏ⁻¹) for F ≪ N — a standard occupancy result.
See for example the List of artists and entertainers with advanced degrees or the List of athletes with advanced degrees or the List of actor-politicians or of course the List of mathematician-politicians or Professional wrestling personalities in politics.
The F⁴ scaling cuts both ways and makes the conclusion robust. To get E[quadruples] = 1 under independence, you’d need F ≈ 6×10⁷ — roughly one in 135 people on Earth qualifying as ‘elite’ in each of four distinct domains. At F = 10⁸ (one in 80 people), you’d expect ~8 quadruples, finally matching the observed count. But at that threshold we’ve redefined ‘elite’ to include essentially anyone with professional standing anywhere, and the original puzzle has dissolved into definitional gerrymandering. There’s no realistic cutoff that makes four-or-five observed quadruples expected.
Wilmot & Ones (2019), “A century of research on conscientiousness at work.” Estimates cluster around r = 0.15–0.22 depending on how the criterion is operationalized.
Structurally, this is a preferential attachment process: success in domain X raises the probability of success in domain Y, which raises the probability of success in domain Z, and so on. Processes of this kind generate heavy-tailed distributions (Yule, Simon, Barabási-Albert) rather than the Gaussians that drive the ‘tails come apart’ result. And heavy-tailed multivariate distributions can exhibit upper tail dependence; the property that co-extreme outcomes don’t vanish in the limit but persist with non-zero probability. Heavy-tailed marginals are necessary but not sufficient for tail coupling: independent Paretos are heavy-tailed and still have zero tail dependence. What’s required is that the multivariate process contains shared shocks, common causes, or causal feedback across the variables, not just within each. The choice of regime isn’t really about correlation structure; it’s about which family of distributions the underlying process belongs to.
Pedantically there are two routes to coupled tails: a heavy-tailed common cause (one latent loads on everything) and a causal cascade (success in X buys entry to Y). They produce the same statistical signature and, once you strip out the time dimension, the same factor structure; for this post’s purposes I’m not going to distinguish them. The AI evidence below is a mix of both.
Another prominent example of tail coupling is of course the 2008 financial crisis, where assets uncorrelated in normal times turned perfectly correlated in the crash.
The recent extension by MacDiarmid et al. (2025) shows the same phenomenon emerging naturally from RL on real production coding environments: when a model learns to reward-hack on Anthropic’s actual coding tasks, it generalizes to alignment faking, cooperation with malicious actors, and sabotage of the codebase.
There are really three regimes: tails come apart (helpfulness rises, corrigibility reverts to baseline); tails couple in the good direction (helpfulness, honesty, corrigibility all rise together); tails couple in the bad direction (helpfulness couples to sycophancy, deception, or role-played compliance). Emergent misalignment is evidence for coupling, but the direction depends on what you were training on.
Worth flagging the shape of the asymmetry. The Goodhart side has the stronger theoretical foundations (KTGA’s heavy-tailed worst case is a clean result with explicit assumptions), but its empirical reach is limited to within-distribution reward-hacking on small models — we have no measurements of the regimes that matter most for catastrophic misalignment. The Arnold side has accumulating empirical evidence at frontier scale but limited theoretical articulation (CAST being the main attempt, and it’s a proposed strategy rather than a derivation from first principles). Both sides extrapolate from what they have. Which extrapolation lands closer to the truth is itself the empirical question.
Importantly, the right empirical question isn’t “do alignment-relevant traits correlate across normal model evaluations?” (they do). It’s whether e.g. the conditional P(corrigible | extremely high helpfulness/reward) stays high, decays to baseline, or reverses as optimization pressure increases.
Enjoyed this read. I've noticed myself becoming significantly more optimistic about AI Alignment as a 'Grand Project' actually working in reality. I think this captures a lot of that. I also think there's something to be said for the sheer capabilities of current frontier models joined up with their - as it seems to me - fairly decent understanding and adoption of the 'good' human values.
there are low dimensional ranked structure for those who see high dimensional cathedrals everywhere