


Researching Alignment Research: Unsupervised Analysis
TL;DR: A mostly-automated Alignment Research Literature analysis resulting from a fun AI Safety Camp project, where I also learned about the value of friendship (that's not in this post though).

Meta-meta: You can also find this here on the Alignment Forum.
Meta: In this project, we collected and cataloged AI alignment research literature and analyzed the resulting dataset in an unbiased way to identify major research directions. We found that the field is growing quickly, with several subfields emerging in parallel. We looked at the subfields and identified the prominent researchers, recurring topics, and different modes of communication in each. Furthermore, we found that a classifier trained on AI alignment research articles can detect relevant articles that we did not originally include in the dataset.
Dataset Announcement
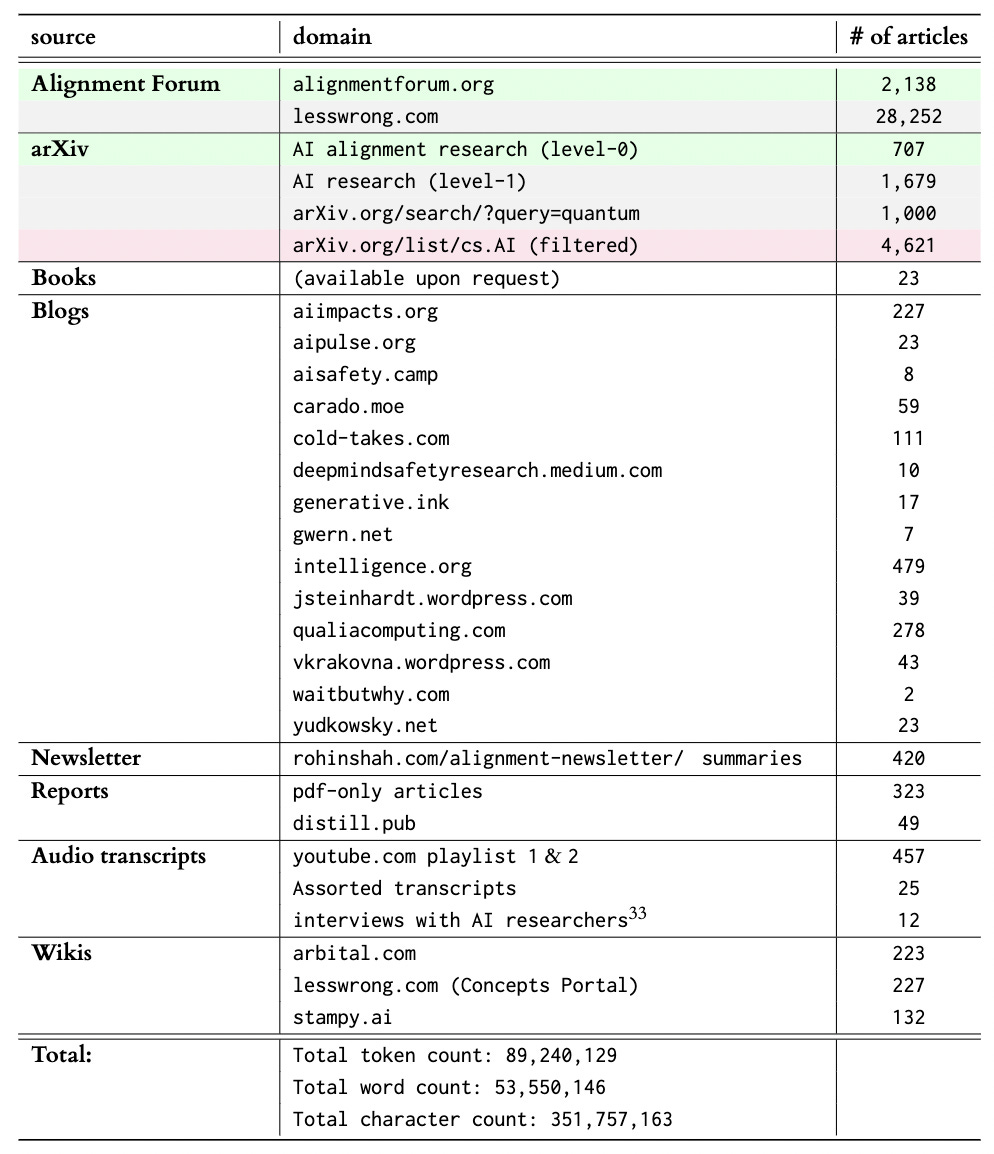
In the context of the 6th AISC, we collected a dataset of alignment research articles from a variety of different sources. This dataset is now available for download here and the code for reproducing the scrape is on GitHub here1. When using the dataset, please cite our manuscript as described in the footnote2.
Here follows an abbreviated version of the full manuscript, which contains additional analysis and discussion.
Rapid growth of AI Alignment research from 2012 to 2022 across two platforms
After collecting the dataset, we analyzed the two largest non-redundant sources of articles, Alignment Forum (AF) and arXiv. We found rapid growth in publications on the AF (Fig. 1a) and a long-tailed distribution of articles per researcher (Fig. 1b) and researchers per article (Fig. 1c). We were surprised to find a decrease in publications on the arXiv in recent years, but identified the cause for the decrease as spurious and fixed the issue in the published dataset (details in Fig. 4).

Unsupervised decomposition of AI Alignment research into distinct clusters
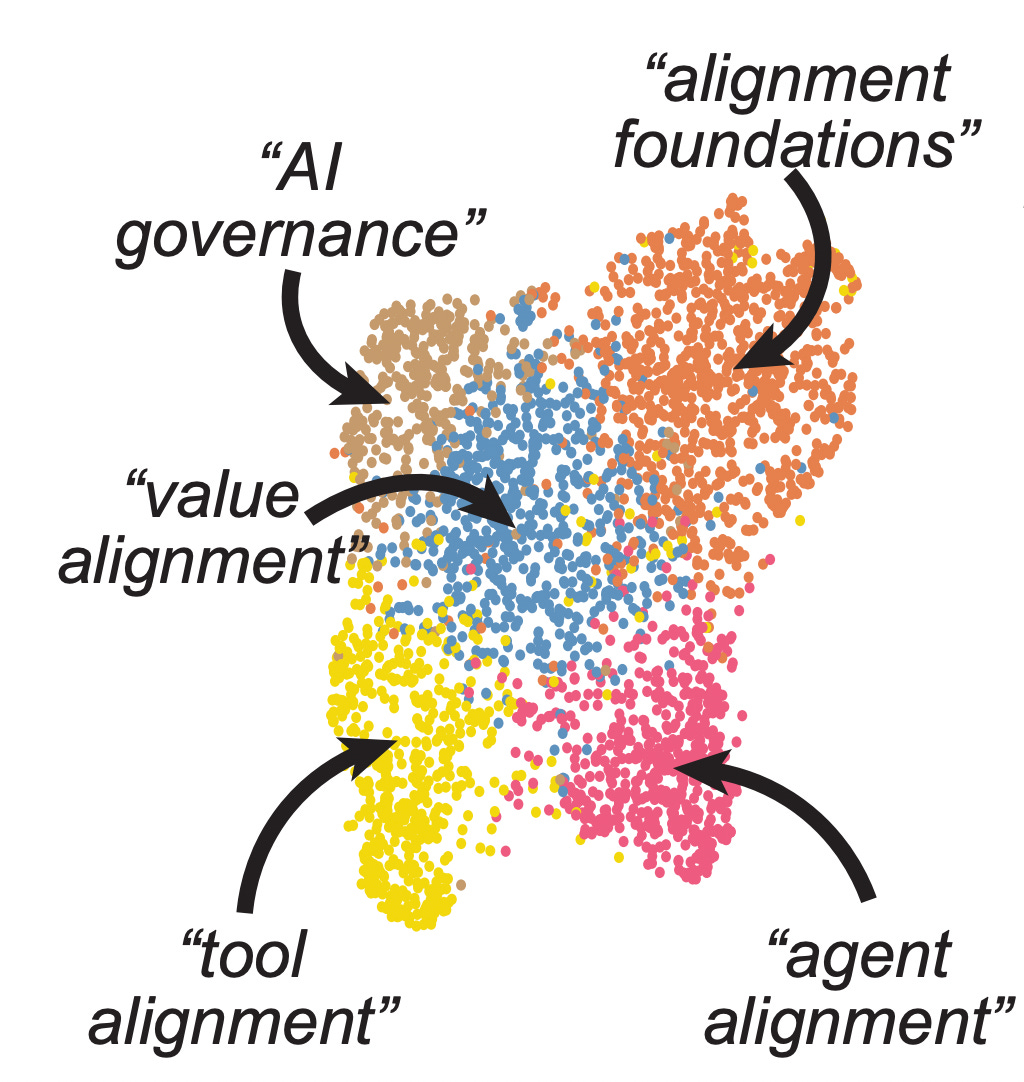
Given access to this unique dataset, we were curious to see if we could identify distinct clusters of research. We mapped the title + abstract of each article into vector form using the Allen Institute for AI's SPECTER model and reduced the dimensionality of the embedding with UMAP (Fig. 2a). The resulting manifold shows a continuum of AF posts and arXiv articles (Fig. 2b) and a temporal gradient from the top right to the bottom left (Fig. 2c). Using k-means and the elbow method, we obtain five clusters of research articles that map onto distinct regions of the UMAP projection (Fig. 2d).

We were curious to see if the five clusters identified by k-means map onto existing distinctions in the field. When identifying the most prolific authors in each cluster, we noticed strong differences3 (consistent with previous work that suggests that author identity is an important indicator of research direction).

By skimming articles in each cluster and given the typical research published by the authors, we suggest the following putative descriptions of each cluster:
cluster one: Agent alignment is concerned with the problem of aligning agentic systems, i.e. those where an AI performs actions in an environment and is typically trained via reinforcement learning.
cluster two: Alignment foundations research is concerned with deconfusion research, i.e. the task of establishing formal and robust conceptual foundations for current and future AI Alignment research.
cluster three: Tool alignment is concerned with the problem of aligning non-agentic (tool) systems, i.e. those where an AI transforms a given input into an output. The current, prototypical example of tool AIs is the "large language model".
cluster four: AI governance is concerned with how humanity can best navigate the transition to advanced AI systems. This includes focusing on the political, economic, military, governance, and ethical dimensions.
cluster five: Value alignment is concerned with understanding and extracting human preferences and designing methods that stop AI systems from acting against these preferences.
We note that these descriptions are chosen to be descriptive, not prescriptive. Our approach has the advantage of being (comparatively4) unbiased and can therefore serve as a baseline against which other (more prescriptive) descriptions of the landscape can be compared (Krakovna's paradigms, FLI landscape, Christiano's landscape, Nanda's overview, ...). Discrepancies between these descriptions and ours can serve as important information for funding agencies (to identify neglected areas) and AI Governance researchers (for early identification of natural categories for regulation).
Research dynamics vary across the identified clusters
We further note some properties of the identified clusters (Fig. 3a). The cluster labeled as "alignment foundations" contains most of the seminal work in the field (Fig. 3b,c), but remains largely disconnected from the more applied "agent alignment" and "tool alignment" research (Fig. 3a). Furthermore, most "alignment foundations" work is published on the Alignment Forum (Fig. 3d) and it has the largest inequality in terms of "number of articles per researcher" (Fig. 3e). This corroborates an observation that was made before: While critically important, alignment foundations research appears to be poorly integrated into more applied alignment research, and the research remains insular and pushed by comparatively few researchers.

Leveraging dataset to train an AI alignment research classifier
After having identified the five clusters, we returned to the issue we noted at the onset of our analysis: the apparent decrease in publications on the arXiv in recent years (Fig. 1a). We were skeptical about this and hypothesized that our data collection might have missed relevant recent articles5. Therefore, we trained a logistic regression classifier to distinguish alignment articles (level-0) from articles cited by alignment articles (level-1) (Fig.4 a). The resulting classifier achieved good performance and generalized well to papers from unrelated sources (Fig. 4b). We then scraped all the articles from the arXiv cs.AI category and asked our classifier to score them (Fig. 4c,d). Based on the distribution of scores of Alignment Forum posts (Fig. 4d) and after skimming the relevant articles, we chose a threshold of 75% as a reasonable trade-off between false positives and false negatives.
When adding the arXiv articles above the cutoff to our dataset, we observed a rapid increase in publications also on the arXiv (Fig. 4e). To test if our clustering is robust to this increase, we repeated the UMAP projection with the updated dataset and found that, indeed, the clusters are still in distinct regions of the manifold (Fig. 4f). Interestingly, the added literature appears to fill some of the gaps between "alignment foundations" and "agent alignment" research.

Closing remarks
The primary output from our project is the curated dataset of alignment research articles. We hope the dataset might serve as the basis for
a semantic search service that returns relevant literature (see prototype here).
writing assistants in the form of fine-tuned large-language models.
projects to preserve AI Safety research in case of catastrophic events.
If you have other ideas for how to use the dataset, please don't hesitate to reach out to us; we're excited to help.
Furthermore, we hope that the secondary outcome from our project (the analysis in this post) can aid both funding agencies and new researchers entering the field to orient themselves and contextualize the research.
As we plan to continue this line of research, we are happy about any and all feedback on the dataset and the analysis, as well as hints and pointers about things we might have missed.
Acknowledgments: We thank Daniel Clothiaux for help with writing the code and extracting articles. We thank Remmelt Ellen, Adam Shimi, and Arush Tagade for feedback on the research. We thank Chu Chen, Ömer Faruk Şen, Hey, Nihal Mohan Moodbidri, and Trinity Smith for cleaning the audio transcripts.
We will make some finishing touches on the repository over the next few weeks after this post is published.
Kirchner, J. H., Smith, L., Thibodeau, J., McDonnell, K., and Reynolds, L. "Understanding AI alignment research: A Systematic Analysis." arXiv preprint arXiv:2206.02841 (2022).
Except for Stuart Armstrong, who publishes prolifically across all clusters.
Remaining biases include:
differences in formatting between arxiv and AF articles that bias the embedding
some (important) topics might not have any documentation due to infohazards
by implicitly focusing on number of published articles (rather than f.e. the "volume occupied in semantic space") we bias our analysis in favor of questions that can be written about more easily
We took the TAI Safety Bibliographic Database from early 2020 as a starting point and manually added relevant articles from other existing bibliographies or based on our judgment. We were very conservative in this step, as we wanted to make sure that our dataset includes as few false positives as possible.