


Via productiva
TL;DR: Introspection on how I do things and which rules and heuristics help me to be productive. Framed as Taleb's via negativa advice. Weaves in a bit of Greek mythology.

Against advice
Be careful whose advice you buy, but be patient with those who supply it. Advice is a form of nostalgia, dispensing it is a way of fishing the past from the disposal, wiping it off, painting over the ugly parts and recycling it for more than it's worth. - Everybody's Free To Wear Sunscreen
…
Yeah, I’m not a huge fan of advice.
I think there are many good side effects of giving and receiving advice. The act of giving advice is essentially an expression of trust, "asking for help" is a social superpower, and the downsides of being exposed to information are usually rather low1. But those are just side effects; the actual core purpose of advice (exchanging relevant and helpful information) is surprisingly hard to get right:
Causality is complicated. Figuring out why you succeeded is hard, and the story you tell yourself about it is probably wrong.
For almost any piece of advice out there, you can find reverse advice, i.e.
“You need to stop being so hard on yourself, remember you are your own worst critic” versus “Stop making excuses for yourself, you will never be able to change until you admit you’ve hit bottom.” SSC
and because of your social bubble, you might be exposed to advice with exactly the wrong polarity2.
The people with the most relevant insight are probably busy doing stuff, leaving the people with a lot of free time on their hands to dominate the advice-giving market. So most people who want to give (or sell) advice do not have the relevant insight to give good advice. This effect corroborates the importance of having mentors; even busy people want to give advice but are more selective about whom they give it to.

Consequently, a lot of advice floating around online and offline tends to be pretty much useless. Even in the rationality community (which gets a lot of other things right), I’m rather put off by “group debugging”, “Hamming circles“, and the “Hammertime”. I see that people get value from doing these things, but most (if not all) value appears to come from the “side-effects” of advice-giving and -receiving rather than the actual content of the advice.
The negative way
Considering all these arguments, I try to limit my advice-giving to an absolute minimum. This, as you can imagine, is becoming increasingly difficult as I continue this experiment of broadcasting my thoughts on a near-weekly basis. There are so many things I want to write about because I think I’ve figured out a truly brilliant way of doing them, but I stop myself so as not to embarrass my future self. Most things that work well for me might be Jan-specific strategies that don’t generalize3.
There might be a way out, however. The great Nassim Taleb declared in 20194
on Twitter. He notices the problem with this a couple of hours later and posts

Nassim calls this strategy fancifully the via negativa, the observation that our knowledge and inherent understanding of downsides is far more robust than what we know about upsides. Instead of telling people what to do, we might want to focus on what not to do. I don’t think this fixes all the issues with advice-giving outlined above, but it goes some distance towards it.
Hence, this post is not regular old advice. It's via negativa. I want to articulate some of the non-obvious productivity traps I have identified in myself and others and warn you about them. Before we dive in, here is a bitter lesson upfront; If your goal is to be productive, you should work and not read blog posts. If you are looking for a way to be productive, stop reading this now and do whatever you're supposed to be doing5.
However, If you happen to be curious about how I do things, read on6.
Don't fight the Hydra.
Perhaps the most common failure mode I observe in myself and others is "getting sidetracked" or "losing focus". It's hard to pinpoint exactly what is happening, so I'll use the (admittedly a bit stale) metaphor of fighting the Lernaean Hydra to illustrate.

Imagine yourself as Heracles sent out to kill the Hydra. For every head you cut off, two new heads grow. As long as the Hydra retains at least one head, you cannot kill it. You can spend a lifetime and more cutting off heads, and you’ll be farther from your goal of killing the Hydra than when you started.
The Hydra, of course, is your research problem. When researching a fact, you might get seduced by trivia and the depths of Wikipedia. When proving a mathematical theorem, choosing the wrong strategy will lead you into an endless circle of algebraic transformations. And in research, more generally, there is a tendency not just to solve a technical problem but to utterly demolish it, i.e., solving every possible variation of the problem and writing a long-winded Tractatus on how you did it.

Be wary, be very wary indeed, of engaging with a Hydra problem. You might be able to identify a Hydra problem by keeping track of the branching factor: how many subproblems does each step of your derivation introduce? If this continues to be larger than 1, your approach is probably incorrect or at least infeasible. This might appear obvious, but history is full of famous examples of researchers getting stuck on epicycles. Researchers produced “pseudo-answers” to questions, but they opened more questions than closed. I observe the pattern in my colleagues, students, and myself7.
One location where I expect a Hydra consistently is data analysis: When performing the wrong kind of analysis (f.e. fitting an HMM with no straightforward latent structure), it is tempting to “try things8” ad infinitum. This is bad because it introduces biases into the analysis and is essentially futile. Improving one aspect of the analysis makes every other aspect worse. Notice the signature of a Hydra problem, and you’re right to be scared.
I found it fruitful to discard the framing and slice reality along different axes in these situations. Instead of fitting an HMM, take a step back and take another look at simple statistics or the raw data. Make your implicit assumptions explicit and modify them. Try to get a “no” instead of a “yes”. And don’t be afraid to shelf something if it doesn’t work9. Otherwise, you can spend an unbounded amount of time and achieve almost10 nothing.
Now, as stated from the onset, this is not positive advice. I do not know how to avoid Hydra-problems in general. Sometimes you do need to dive into the depths of Wikipedia, fight your way through increasingly complicated algebraic equations, or utterly demolish a technical problem - only to come out at the other side and to find the branching factor collapse suddenly. And sometimes all the new heads of the Hydra that emerge turn out to be deep and important problems that can be (approximately) separated from each other. But unless the problem you solve is so important that you’re okay with spending a lifetime without making progress, don’t risk engaging with a Hydra problem.
One must imagine Sisyphus unproductive.
I’ve spent an insane amount of time in the early 2000s manually adding thumbnails to my music collection in Windows Media Player11.

In retrospect, I did that because the resulting mosaic of album covers looked kind of pretty. But at the time, I told myself that this is a one-time investment of work and that once I’ve updated my entire library, I’ll only have to do a little bit of work to add the cover art for every new album I add. You can imagine my disappointment when Spotify appeared and made my thumbnail work useless. I’m not bringing this up because I still hold a grudge12. It’s just an illustrative example of what I call “overoptimizing in null space”.
Let’s take that apart a bit further. You are probably already familiar with the 20-80 rule: “Focus on the vital 20% of effort that produces 80% of the outcome."13 That rule is great, but it’s not “constructive” and doesn’t help with finding the vital 20%. Also, there are some situations where we cannot apply the rule straightforwardly:
When writing an essay for your dream college or doing a work test for your dream job, you might not want to half-ass it. This is not a situation where you can aim for a fixed level of quality and get the job - by construction, you are competing with other people who are incentivized to outbid you. So if you value the opportunity sufficiently and think you have a shot at outbidding your competition, you don’t want to stop at 20% effort. Here, the landscape is artificially designed to incentivize you to demonstrate the maximum of what you are capable of (which the interviewer is trying to estimate)14. The goal of your effort is not to solve a problem in the world but to signal your capability.
Sometimes the Pareto principle does not apply. Sometimes the outcome is proportional to the effort. Or at least it takes a very long time before diminishing returns become noticeable. There might still be reasons not to invest 100% effort 100% of the time, but those are a lot less straightforward than “if you want more of something, do more to get it”.
And then there is Yoda and “Trying to Try”. Sometimes it is simply a convenient trick to think of your effort as an “all-out effort” rather than to invest the cognitive overhead in calibrating how much effort you should be investing. This only works when the task is sufficiently important.
These counterexamples motivate me to think of “optimization in null space”. In linear algebra, the null space is the part of the input space mapped onto 0. As long as you move in this null space (or an affine transformation), your outcome will not change. If you’re more of a visual thinker, think of a 2D Mexican hat15 that has a circular basin of minima.
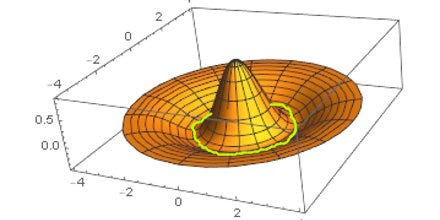
“Optimization in null space” is then an oxymoron that gestures at the idea of spending a lot of energy on something that doesn’t cash out in terms of performance. This is essentially equivalent to the 20-80 rule but framed in terms of optimization processes. Interpreted through that lens, there are a few non-obvious heuristics that pop out:
Try to reduce overhead aggressively. Go for systems with minimal structure and maximal flexibility. Don’t search for the perfect note-taking system; pick something and run with it. “A complex system that works is invariably found to have evolved from a simple system that worked.” If it doesn’t start paying off soon after starting, you might be in null space16.
Look for things that scale. Effective altruism is a community built around searching for good things that scale. Meeting new people scales. Starting new projects scales17. Artificial intelligence scales18.
When things start to feel noisy, but you haven’t reached your desired outcome yet, then go for small, robust improvements rather than trying to revolutionize19. This must be how Deepmind built AlphaCode. To reach this point, you must be slightly desperate.
But those are, of course, only heuristics. “Via negativa” does not provide a rulebook to follow; it just tries to highlight major pitfalls. Noticing the pitfalls and avoiding them is up to you.
Don't listen to Cassandra.
There is a chance that I’m taking this Greek mythology thing too far. Let me be clear, if you find someone who really, legitimately is Cassandra, please do listen to them. Also, please correct your bias of not believing women. Also, if people talk to you, please listen to them or (alternatively) tell them you have to visit the bathroom or something. Just “not listening” is rude.

Instead, I’m trying to say that there is an overwhelming “Everything” going on online, and our poor monkey brains cannot keep track. Therefore you need really good filters. Try having fewer opinions, resist the urge of joining the debate du jour, ignore most things that don’t make sense to you right now. It’s okay, and you’re only human. Somebody else (hopefully) will take the stuff you discard seriously. And if it were really important, it would probably pop up again and again.
The edgelord-y version of this idea is Sturgeon's law: “ninety percent of everything is crap20.” I like the slightly more palatable “ninety percent of everything is not immediately useful to you.” That version is also more likely to be true: It would be weird if most things out there were relevant to you in particular, and even the objectively worst piece of science fiction probably made someone’s grandma very proud.
What are the properties of a good filter? A really good filter will only let the first-order approximation of a concept get into long-term memory. You won’t need more to plant the concept into your ontology, and if you ever need higher-order terms (f.e. for writing), you’ll have to go back to the source anyway. Your filter might also be very sensitive to bullshit and discard most anecdotes. Instead of tracking details, track motivations.
And, please, do all of that without being rude.
Closing thoughts
Even though I presented them as three different ideas (don’t try to solve Hydra problems, don’t optimize in null space, don’t try to pay attention to everything), they all circle around one common theme: be honest with yourself about your limitations, notice when you're going down a rabbit hole, and constantly recalibrate. Try to have a good epistemic.
Phrased like this, I don’t think this advice21 is controversial (or very novel22). The value I gained from writing this is that I now have a more explicit understanding of how I operate (sometimes/rarely). The value for a hypothetical reader that has come to this point might be that they update23 on the relative importance of my advice over other people’s advice. Or perhaps you feel motivated to make your M.O. explicit? Feel free to leave your thoughts in the comments; always curious to hear what you think (most things people tell me directly pass my filter just fine). Or consider signing up for the newsletter to get notified whenever I write something new!
Unless somebody manages to trick you into bear-assisted suicide.
I.e. addicts that are part of a drug culture might get the advice to take more drugs. Or rationalists might get the advice to use more rationality techniques.
And that might stop working as soon as external factors in my environment change.
I.e. “forever ago” in internet years
You're welcome!
I also hope that the first group of people continues to read, reverse psychology and everything.
I don’t want to step on anybody’s toes, but if I had to register a prediction, I’d predict that the ELK problem turns out to be a Hydra problem. It appears to explode in complexity with every partial “pseudo-answer” provided.
Cleaning data, changing the number of hidden states, transforming the representation of the observations, changing hyperparameters of the fitting algorithm, and repeating.
This is where “do all the things” becomes important. You need to have multiple projects running in parallel to have the freedom of shelving the ones that don’t work.
I’m saying almost because even Herkules would probably improve his monster-killing ability through fighting the Hydra for years at end. Some of the skills should transfer, as long as you eventually turn to a non-Hydra problem.
I don’t know if this is a German thing or a more general phenomenon.
I never forgive, but I do forget eventually.
Related is the strategy to, in the words of Nate Soares, “half-ass it with everything you've got“.
There is some super interesting game theory here. These interview situations appear to be all-pay auctions where the Nash equilibrium becomes unstable when the bidders' valuation is higher than their budget? This leads to a bad situation where interviewees waste a lot of time and energy (all-pay) on jobs they won’t get. The interviewers get unrealistic estimates of what the candidates are capable of (nobody can sustain 100% effort). A much nicer equilibrium would be if all the interviewees agreed only to put 20% effort into the interview. They’d waste less energy, and the interviewer would get a more realistic estimate of what they’ll get. But this equilibrium is unstable because each interviewee is incentivized to put in more effort to beat their competition.
Can we design a system that avoids this bad dynamic?
This term feels inappropriate, and Wikipedia calls it the “Ricker wavelet” or the “Marr wavelet”. And I guess it’s a silly stereotype to associate the sombrero so strongly with Mexico?
But what about a university education? Or learning an instrument? Or the marshmallow test? Here I’m happy to bite the bullet and assert that it’s probably a bad idea to continue if you don't enjoy uni. If you don’t enjoy the process of learning an instrument, you’re probably doing it wrong, and too many marshmallows are bad for you.
In the sense that your total expected outcome continues to increase even if your performance across all the individual projects deteriorates moderately.
This is (part of) why I am excited about automated research and digital assistants.
Here’s an anecdote that I’m dying to share: At uni, I took part in a General Game Playing where each team had to program a (good-old-fashioned) A.I. that can solve a range of games after only being provided with the rules at runtime. The only feasible strategy (AFAICT) is to do a pure search on the state space of the game (provided at runtime). There was pretty fierce competition, and some teams packed their general game player with a bunch of heuristics to try and guess (at runtime) which game they were playing so that they could do their search of state-space more efficiently. Our team didn’t do that. Instead, we read the programming language's documentation carefully and wrote a highly optimized version of vanilla alpha-beta search that exploits all the built-in functions. Our team beat all the other teams by a pretty substantial margin. (I have a hard time hiding that I consider that piece of coursework from my undergrad to be the peak of my research career).
It’s important to remember that Theodore Sturgeon was a science fiction author and critic. Someone who gets paid to say and write interesting things, not someone who gets paid to say and write true things.
Yeah, I admit that that is what the essay turned into. Shame on me.
As noted, I was mostly remixing/slightly modifying Thomas Kuhn’s scientific paradigms, the 20-80 rule, and Sturgeon’s law.
I’m staying intentionally unspecific about the direction of the update.
Nicely put! I guess it explains why my sons never listen to my advice.
To add one piece of my own negative advice: Don't ignore all advice, because sometimes it can be really valuable. :) In 2003, I read a book about writing, called "So, You Want to Write a Novel" by Lou Stanek. It wasn't exactly unasked-for since I bought the book, but it was full of positive advice that wasn't in any way specific to my own personal situation. I followed it anyway and wrote my first book. Nobody cared. The book told me to not give up and try again. I wrote another book, and another. Both got rejected. By that time I was beyond caring, writing was just too much fun. Book #4 got published and became a bestseller. Meanwhile I have published more than 50 novels and children's books and can afford to be a full-time writer.
What can you learn from this? Nothing, unless you want to be a writer too, in which case I recommend you read the book. But I love to give unwanted advice! :)
Soundbites are annoying, but a great way to get out of it is possibly this: given two quotes that seems to contradict one another, it is more likely that they are applied in opposite or non-overlapping situations, or that there is a regulative feedback loop to be aware of. https://rogersbacon.substack.com/p/eponymous-laws-part-1-laws-of-the?s=r