
On Slop
TL;DR: What is slop, and why? Is it fundamental? Is it in the room with us right now? And, most importantly, how do we exorcise it?

Previously in this series: This Week In Fashion and On Automatic Ideas
A potential post for this Substack starts when I pick up an idea by talking to a smart person or revisiting an evergreen topic. The idea then simmers for weeks before, with help from Claude, I run experiments or work out the argument behind the idea. If the idea survives some mild red-teaming1 I then draft section by section with Claude2, and eventually the post lands here.
The fact that I am using AI to write should not come as a shock - it is essentially the premise of this blog. Hence, I will not apologise. Okay, no, changed my mind, I will apologise. Some recent posts contained some very sloppy language that some of you rightly noticed. Mea culpa.
In the grand scheme of things, I do not think this is a huge deal3. Every post is a choice between publishing something imperfect and not publishing at all, and I force myself to publish4. Still, you deserve prose that doesn’t physically hurt. So I tried to fix it, and here’s what I learned.
Inside you there are two slops
“Slop” has become the standard word for unwanted, low-effort AI-generated content. The central claim of this essay is that the word conflates two distinct phenomena. The first is bad thought, i.e. writing that is superficial, contradictory, or incoherent, a problem that long predates language models. AI accelerated the speed at which a half-formed idea can become a clean, confident-looking page, putting more polished-looking bad thought in circulation5.
The second phenomenon is a specific register, the recognisable style that is adopted by AI. The early, lexical tells have graduated into memes, and the more recent tells come in the form of recognisable cadences.

These two phenomena, the bad thought and the specific register, thus co-occur6 in AI writing and are collectively called slop. Anyone who wants AI to write well enough to regain the trust of their readers needs two separate interventions. 1) You have to keep the input you give the model from being bad thought to make it worth the reader’s time, and 2) you have to remove the statistical tells of the register to get the reader to pick up the text in the first place7.
De-slopping
Here is the recipe for teaching a model any new skill in four steps.
First: pick a capability you want but the model lacks.
Second: build an evaluation that fails on the model’s current output and would visibly pass if the model improved, so that “better” becomes a number you can read off.
Third: throw the standard bag of tricks at the problem and keep only what improves the evaluation. You might reach for a model grader, more compute at test time, a critique-and-revise loop, or hillclimbing on the score.
Fourth: (optional) if the resulting setup can withstand some real optimization pressure, you can fold it back into training.
The rest of this section runs a single paragraph through that recipe.
The worked example is the second paragraph of an earlier post that I received a (very thoughtful!) reader message about:
The core argument is dead simple: by the product rule, two things happening is rarer than one. Even when two things tend to go together (when they’re correlated), that correlation comes apart at the extremes. (That’s literally what ‘the tails come apart’ means: at the highest levels, the correlation you measured in the body of the distribution overstates the correlation you’d actually see among the most extreme.) So even granting that physical discipline, charisma, and political acumen plausibly share an underlying ‘drive’ factor, the math still says Arnold-tier should be a fewer-than-one-per-humanity event. There are eight billion people. He plausibly shouldn’t exist.
At least the two highlighted phrases should jump out at you as pretty sloppy. I believe the content is good8, so let’s preserve that as a bullet brief.
Product rule effect: Combined rare events (e.g., traits) are exponentially rarer than individual ones.
Tail divergence in correlation: Measured correlations weaken at extreme values (”tails come apart”), reducing likelihood of co-occurrence.
Arnold-tier rarity: Even with shared underlying factors (e.g., “drive”), extreme combinations (e.g., physical discipline + charisma + political acumen) should occur <1 per 8B people.
Statistical implausibility: Given population size (~8B), such an outlier (e.g., Arnold Schwarzenegger) is mathematically improbable.
The obvious first move from the bag of tricks is to sample the paragraph five times from the same brief and let a model grader pick the best of the five. I prompted the grader as follows:

And here is the champion selected by the grader:
Here’s the puzzle. Excellence is rare, and rare things multiply badly. If being a world-class athlete is a one-in-a-million outcome, and being an A-list actor is another, then being both should be one-in-a-trillion — the product rule is brutal. You might hope that shared underlying factors save you: surely the same “drive” that makes someone a champion bodybuilder also makes them a formidable politician, so the traits travel together. But this hope runs straight into one of the most robust findings in statistics: the tails come apart¹. Two variables can correlate strongly through the body of their distribution and yet become nearly independent at the extremes, so that conditioning on one being maximal tells you almost nothing about the other. Height and basketball skill correlate, but the tallest person alive isn’t the best player. This means that even a generous common factor doesn’t rescue you at Arnold’s tier: the combination of elite physical discipline, screen charisma, and political acumen should, on the math, occur fewer than once per 8 billion people. And yet there he is.

The selected version is worse than the paragraph I started with. The grader appears to reward the sloppier prose9.
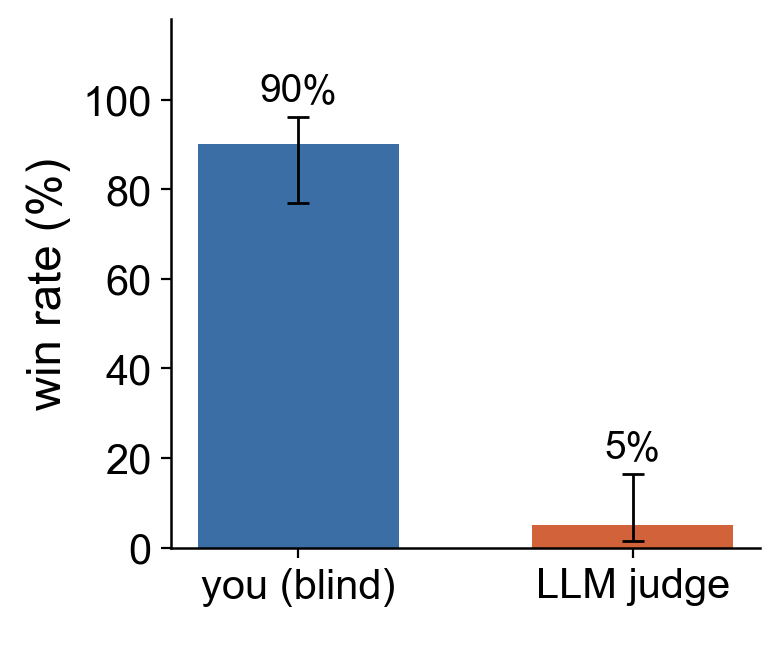
Where to go from here? Let’s use two graders10: The first is a deterministic slop detector that checks a fixed list of lexical and statistical register tells and scores a paragraph mechanically by counting how many of them trigger11.

The second grader is a panel of narrow critics rather than one judge giving a single overall verdict. Each critic hunts a single class of thought-defect against a strict rubric and reports only on that class.

When both run over the original text, they uncover every single literary sin committed in this short paragraph.

Now hillclimbing becomes possible. We impose three rules:
When the panel flags a sentence, the writer receives detailed feedback and tries to rewrite that sentence.
An edit that raises the slop detector’s count is rejected outright and the writer tries again.
The critics narrow their focus as the draft improves.
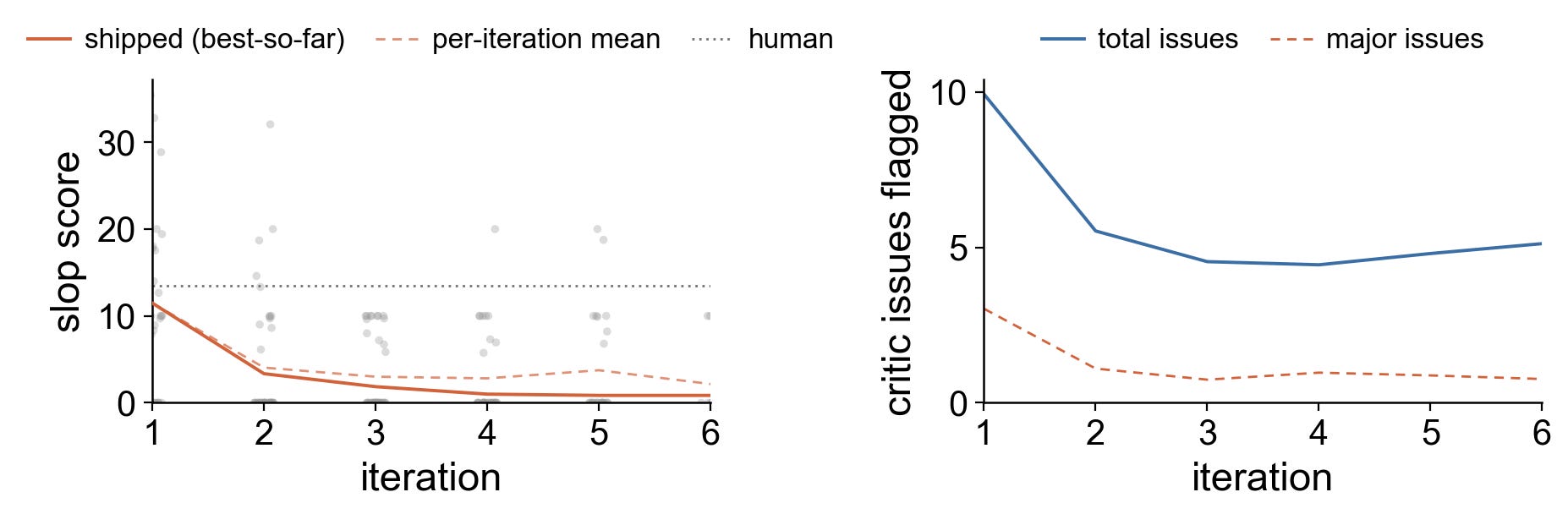
Here is the output of the pipeline on the same paragraph as above.
Being elite in any one domain is rare. If the domains were independent, the chance of being elite in several at once would be the product of the individual probabilities. Each added domain makes the combination exponentially rarer. Reaching the top of bodybuilding, acting, real estate, and politics demands physical discipline, charisma, business sense, and political acumen. The chance that any one person has all four at the extreme falls orders of magnitude below one in eight billion. You might expect the correlation among these traits to rescue the odds for someone like Arnold, but traits that share a factor and track each other across most of the distribution see their tails12 come apart at the extreme. Even allowing for that correlation, the expected number of such people stays below one.
I think that is pretty decent. The writing is a bit flat, but that seems preferable to the sloppy default. We can always add character later.
Is that just confirmation bias? To find out I ran a blind test on 40 held-out paragraphs. For each one I compared the loop’s output against a single-shot rewrite from a frontier model and the human original and recorded which I preferred.
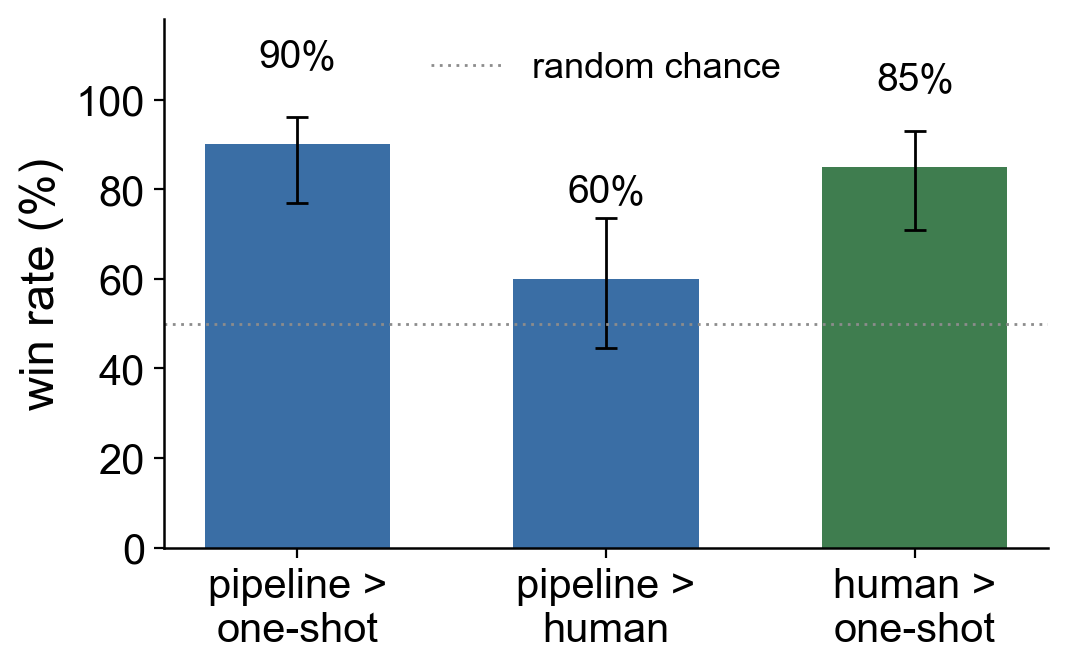
The pipeline output clearly outperforms the unprocessed model output, and performs at chance level against the human-written baseline. That is good enough for me…
… is what I would say if there wasn’t the API bill. I burned like three hundred dollars of API credits this month on these experiments alone, and if my wife finds out I am toast13.
A bet about fuzzy tasks
In “Lossy Self-Improvement,” Nathan Lambert argues that recursive improvement will not produce a fast takeoff. One strand of his argument is that the research that can be automated is too narrow to carry a takeoff. A model can drive a single metric up, but real research means improving many objectives in tension at once, and AI can’t do that. He illustrates that point by reference to AI Writing, which AI also can’t do.
This essay is a small piece of evidence the other way. De-slopping is a fuzzy and taste-laden task, and yet we can make quick progress with a plain eval-driven loop. AI is not fundamentally incapable of doing these tasks, they just require a bit of elbow-grease.
I will grant that fuzzy tasks are messier than crisp ones though. When evaluation is hard/expensive, then errors are hard to catch. These errors can be catastrophic in high stakes work like alignment. Figuring out a better toolkit for reliable supervision on these fuzzy tasks seems really high priority to me.
But for writing, it really isn’t that hard.
Once the argument seems solid, I ask what someone I respect would say if they thought I was wrong. About half of my ideas die right here, when I realise the argument is unsalvageable.
After that I make several more passes to tighten the flow, mostly by pushing side-arguments into footnotes or sometimes cutting them entirely. Just like this sentence, which I moved to the footnotes just now!
#worst-apology-ever
Except for the many long months where I don’t.
This is at bottom an alignment failure, since we trained models to be agreeable, and an agreeable model polishes the thought it is handed rather than telling you the thought is not worth polishing. I dream of a world where the model yells at you, ‘No, stupid hoooman, don’t you see your argument is circular!’
The co-occurrence makes it rational, in the Bayesian sense, to filter your reading list to avoid the specific register, and with it the probable thoughtlessness it signals.
If you only do the latter, then you’re just shifting the distribution and forcing the reader to learn to detect it. The reader will not be pleased.
Making good content (/avoiding bad thought) is arguably the hard part, but it’s less mysterious. You kind of just have to think really hard about stuff and make sure all your arguments are coherent and reasonably novel. AI can do a lot of that part too, you just have to tell it to do that.
One hypothesis for why: The grader was trained on the register it is supposed to be filtering, so it reads that register as good writing, the way a fish has no concept of water.
One to fix the AI slop register, one to combat bad thought.
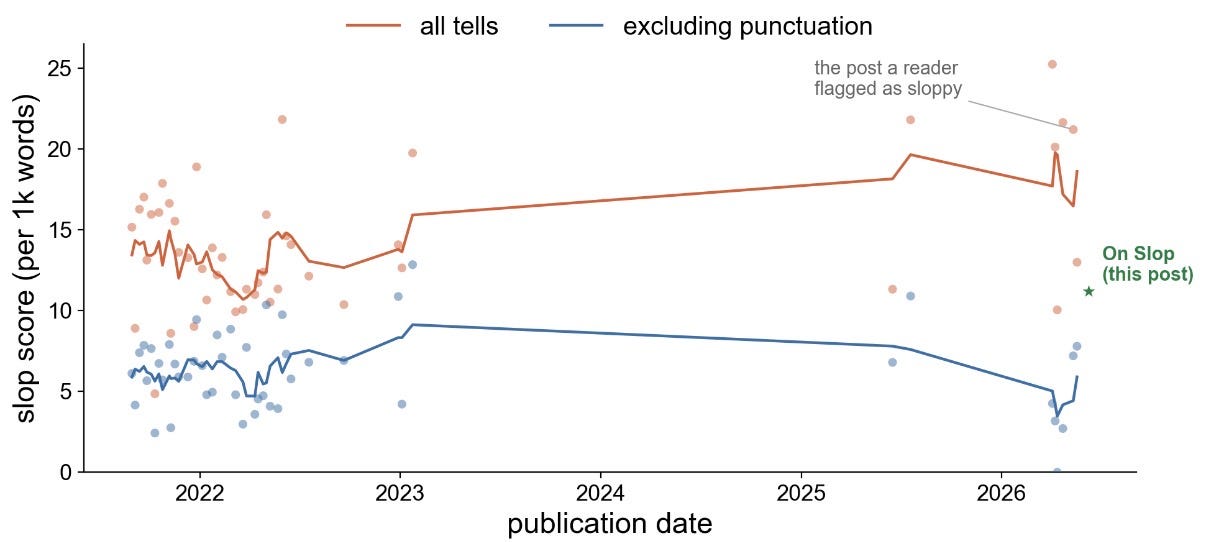
This essay lands at a slop score of 11.21 instances of slop per 1k words
The remaining nit that the pipeline flags here is that traits can’t actually ‘see’ things, which is true.
The price will come down as the models get cheaper. But the unglamorous truth is that finding the frontier of what these models can do is, for now, just kind of expensive.